If you’re uploading data straight into ClickHouse, it works best ingesting large chunks (a good starting point is 100,000 rows per chunk) of data in a single query. Additionally, there are many other ways of ingesting data via kafka or from other external sources such as S3. The standard process is to ingest the data into a single table for long-term storage and then use materialized views to transform this in real-time into aggregate tables for easier display to customers and smaller storage requirements. But, even if this is working fine in production you may still have times when you need to manipulate tables individually.
Lets imagine that somehow you dropped some data and you need to insert it manually later on. If you are using normal bulk upload this is perhaps not too difficult, however if you are pulling from Kafka or some other in-ClickHouse process you will need to create a new flow to insert into the main table. Perhaps somehow your main storage table is missing rows but they managed to get aggregated. Or perhaps you want to rebuild your aggregates from the main storage table without having to build new views for them. Or perhaps you want to change the way you are fetching or pre-processing the data, but have the two different processes running side by side to handle old and new traffic.
When you have a critical production issue you need to be able to react as quickly and be as flexible as possible, so it’s good at the initial architecture stage to build some flexibility into your data ingress pipelines.
With all these possibilities in mind, the Null table engine comes in very useful. But, as its name suggests the Null table engine drops any data put into it. So how can it be useful? The secret is the magic of ClickHouse’s materialized views – if you insert data into a Null table it doesn’t get stored anywhere, but it does get passed on to the attached materialized views. So, Null tables are a good way to add layers of indirection into the data ingress process.
Lets say you want to take data from kafka, store it in a table and run some aggregations on this data (via materialized views) to produce reports. The easy way would be:
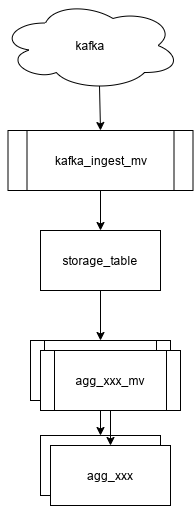
But for ultimate flexibility we would usually recommend adding Null tables at the following points:
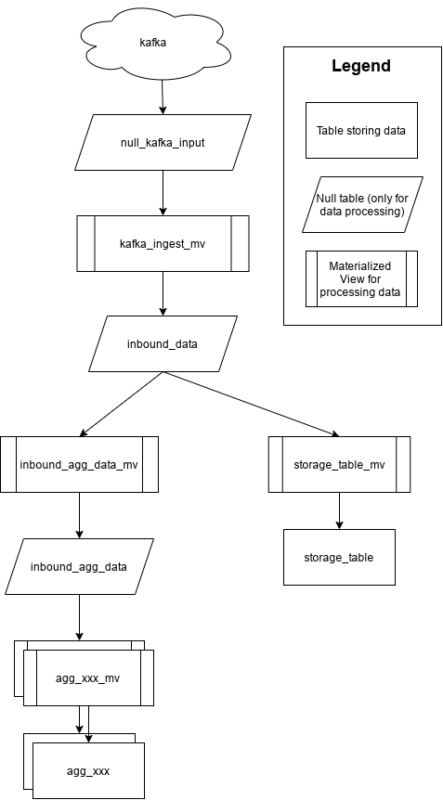
These three null tables mean that if you want to store and hold kafka data for some reason you can use the null_kafka_input table. if you want to insert (processed) new data into the whole system you can insert it into inbound_data. If you want to remove a set of data from your aggregates and re-insert from your storage table you can insert into the inbound_agg_data.
How do you create these null tables? It’s as simple as:
create table inbound_data ENGINE=Null AS SELECT * FROM storage_table LIMIT 0; CREATE MATERIALIZED VIEW inbound_data_mv TO inbound_data AS SELECT * FROM storage_table;
It’s also pretty straight forward to modify an existing system to add these in – you first need to add them in, then modify each of the materialized views to read/write to the tables correctly. This can be done with very minimal downtime.
Putting these Null tables at key points in the data ingest chains adds virtually no overhead to normal operations but allows you much more flexibility in maintenance and disaster scenarios.